bench is now available on CRAN!
The goal of bench is to benchmark code, tracking execution time, memory allocations and garbage collections.
Install the latest version with:
Comparison vs existing methods
Compared to other methods such as [system.time], rbenchmark, tictoc or microbenchmark we feel it has a number of benefits.
- Always uses the highest precision APIs available for each operating system (often nanosecond-level).
- Tracks memory allocations for each expression benchmarked.
- Tracks the number and type of R garbage collections per expression iteration.
- Verifies equality of expression results by default, to avoid accidentally benchmarking inequivalent code.
-
bench::press(), a function which allows you to easily perform and combine benchmarks across a large grid of values. - Uses adaptive stopping by default, running each expression for a set amount of time rather than for a specific number of iterations.
- Expressions are run in batches and summary statistics are calculated after filtering out iterations with garbage collections. This allows you to isolate the performance and effects of garbage collection on running time (for more details see Neal 2014).
Usage
bench::mark()
Benchmarks can be run with bench::mark(), which takes one or more expressions to benchmark against each other.
bench::mark() will throw an error if the results are not equivalent, so you don’t accidentally benchmark inequivalent code.
## Error: Each result must equal the first result:
## `[` does not equal `[`Each result must equal the first result:
## `dat` does not equal `dat`Each result must equal the first result:
## `dat$x > 500` does not equal `which(dat$x > 499)`Each result must equal the first result:
## `` does not equal ``Results are easy to interpret, with human readable units.
## # A tibble: 3 x 6
## expression min median `itr/sec` mem_alloc `gc/sec`
## <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
## 1 dat[dat$x > 500, ] 441µs 466µs 2032. 377KB 12.5
## 2 dat[which(dat$x > 500), ] 363µs 378µs 2619. 260KB 12.5
## 3 subset(dat, x > 500) 552µs 573µs 1730. 509KB 14.8By default the summary uses absolute measures, however relative results can be obtained by using relative = TRUE in your call to bench::mark() or calling summary(relative = TRUE) on the results.
## # A tibble: 3 x 6
## expression min median `itr/sec` mem_alloc `gc/sec`
## <bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 dat[dat$x > 500, ] 1.22 1.23 1.17 1.45 1.00
## 2 dat[which(dat$x > 500), ] 1 1 1.51 1 1
## 3 subset(dat, x > 500) 1.52 1.52 1 1.96 1.18
bench::press()
bench::press() is used to run benchmarks against a grid of parameters. Provide setup and benchmarking code as a single unnamed argument then define sets of values as named arguments. The full combination of values will be expanded and the benchmarks are then pressed together in the result. This allows you to benchmark a set of expressions across a wide variety of input sizes, perform replications and other useful tasks.
set.seed(42)
create_df <- function(rows, cols) {
as.data.frame(setNames(
replicate(cols, runif(rows, 1, 1000), simplify = FALSE),
rep_len(c("x", letters), cols)))
}
results <- bench::press(
rows = c(10000, 100000),
cols = c(10, 100),
{
dat <- create_df(rows, cols)
bench::mark(
min_iterations = 100,
bracket = dat[dat$x > 500, ],
which = dat[which(dat$x > 500), ],
subset = subset(dat, x > 500)
)
}
)## Running with:
## rows cols## 1 10000 10## 2 100000 10## 3 10000 100## 4 100000 100## # A tibble: 12 x 8
## expression rows cols min median `itr/sec` mem_alloc `gc/sec`
## <bch:expr> <dbl> <dbl> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
## 1 bracket 10000 10 1ms 1.03ms 959. 1.13MB 21.8
## 2 which 10000 10 554.37µs 578.96µs 1705. 572.7KB 19.5
## 3 subset 10000 10 1.13ms 1.18ms 841. 1.25MB 21.9
## 4 bracket 100000 10 14.35ms 14.54ms 68.2 11.16MB 45.4
## 5 which 100000 10 9.54ms 9.75ms 102. 5.44MB 23.8
## 6 subset 100000 10 15.25ms 15.39ms 64.8 12.3MB 48.9
## 7 bracket 10000 100 7.99ms 8.08ms 123. 9.68MB 66.0
## 8 which 10000 100 3.04ms 3.24ms 306. 3.96MB 39.8
## 9 subset 10000 100 8.1ms 8.25ms 120. 9.8MB 46.8
## 10 bracket 100000 100 73.59ms 75.36ms 12.7 97.09MB 47.3
## 11 which 100000 100 27.91ms 28.34ms 32.9 39.84MB 16.9
## 12 subset 100000 100 74.15ms 75.06ms 13.0 98.24MB 48.9Plotting
ggplot2::autoplot() can be used to generate an informative default plot. This plot is colored by GC level (0, 1, or 2) and faceted by parameters (if any). By default it generates a beeswarm plot, however you can also specify other plot types (jitter, ridge, boxplot, violin). See ?autoplot.bench_mark for full details.
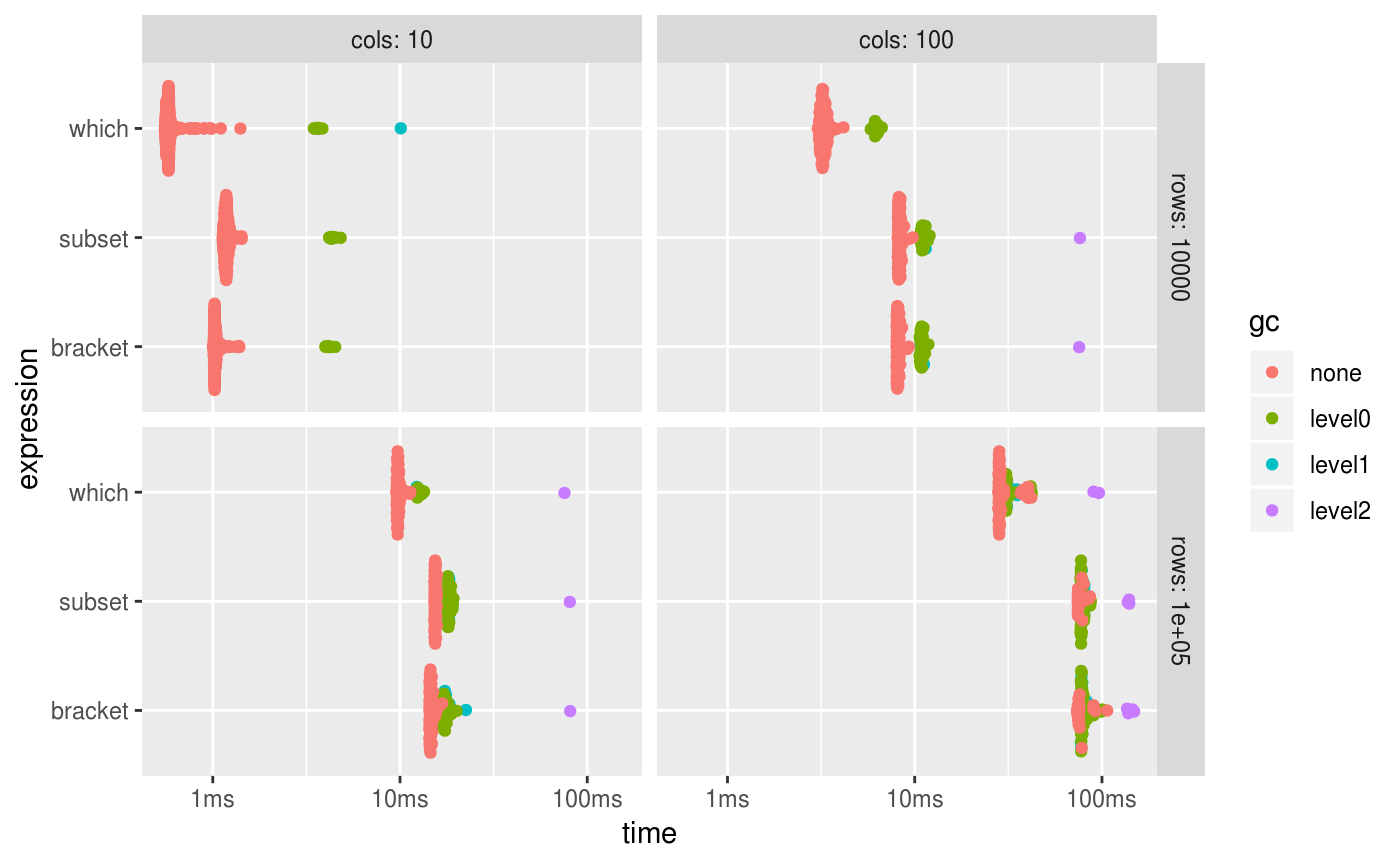
You can also produce fully custom plots by un-nesting the results and working with the data directly.
library(tidyverse)
results %>%
unnest() %>%
mutate(expression = as.character(expression)) %>%
filter(gc == "none") %>%
ggplot(aes(x = mem_alloc, y = time, color = expression)) +
geom_point() +
scale_color_brewer(type = "qual", palette = 3)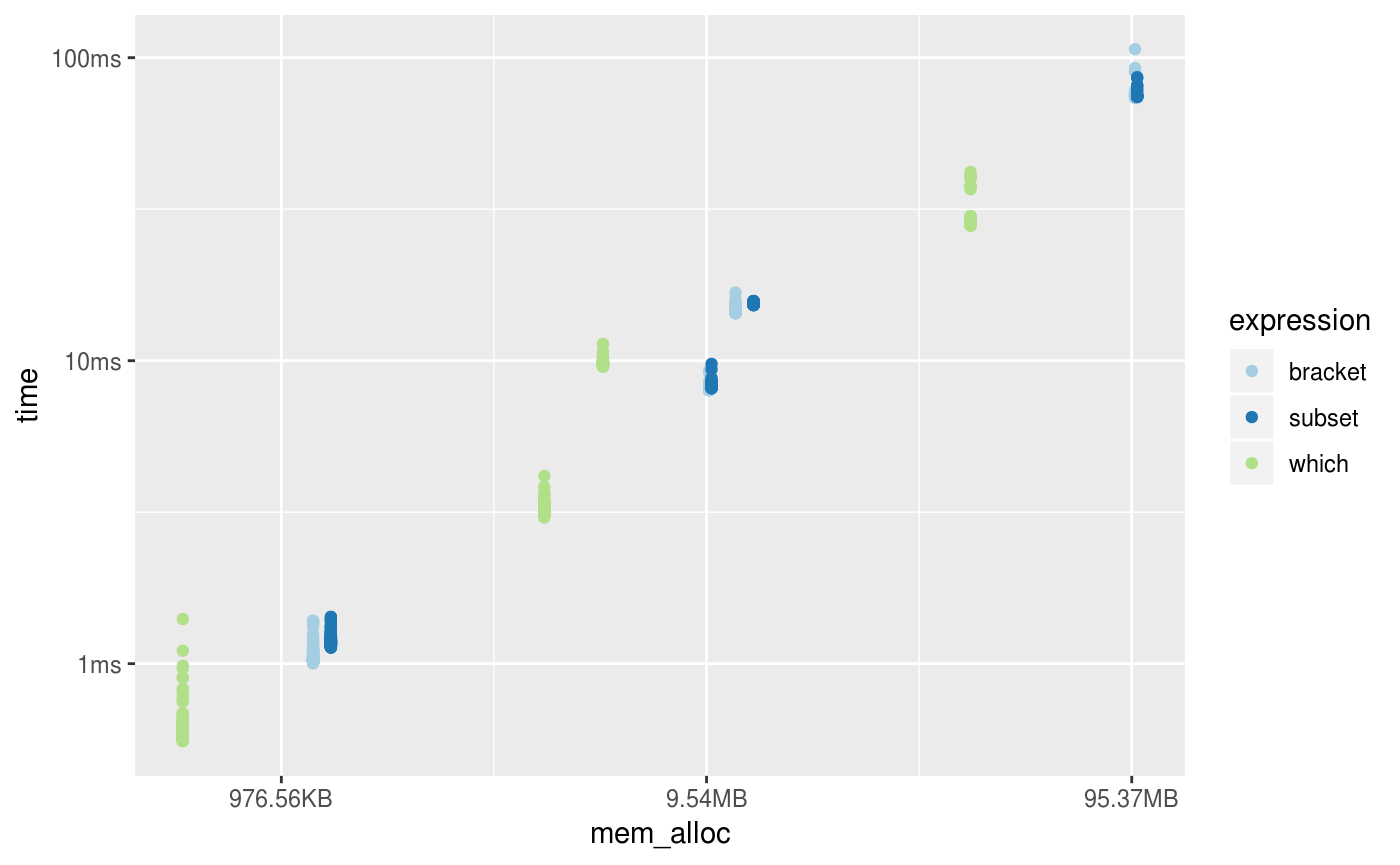
Dependency load
When the development version of bench was introduced a few users expressed concern over the number of dependencies in the package. I will attempt to explain why these dependencies exist and why the true load may actually be less than you might think.
While bench currently has 19 dependencies, only 8 of these are hard dependencies; that is they are needed to install the package. Of these 8 hard dependencies 3 of them (methods, stats, utils) are base packages installed with R. Of these 5 remaining packages 3 have no additional dependencies (glue, profmem, rlang). The two remaining packages (tibble and pillar) are used to provide nice printing of the times and memory sizes and support for list columns to store the timings, garbage collections, and allocations. These are major features of the bench package and would not work without these dependencies.
The remaining 11 packages are soft dependencies, used either for testing or for optional functionality, most notably plotting.
Feedback wanted!
We hope bench is a useful tool for benchmarking short expressions of code. Please open GitHub issues for any feature requests or bugs.
Learn more about bench at - http://bench.r-lib.org